Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Gadgets & Lifestyle for Everyone
Gadgets & Lifestyle for Everyone
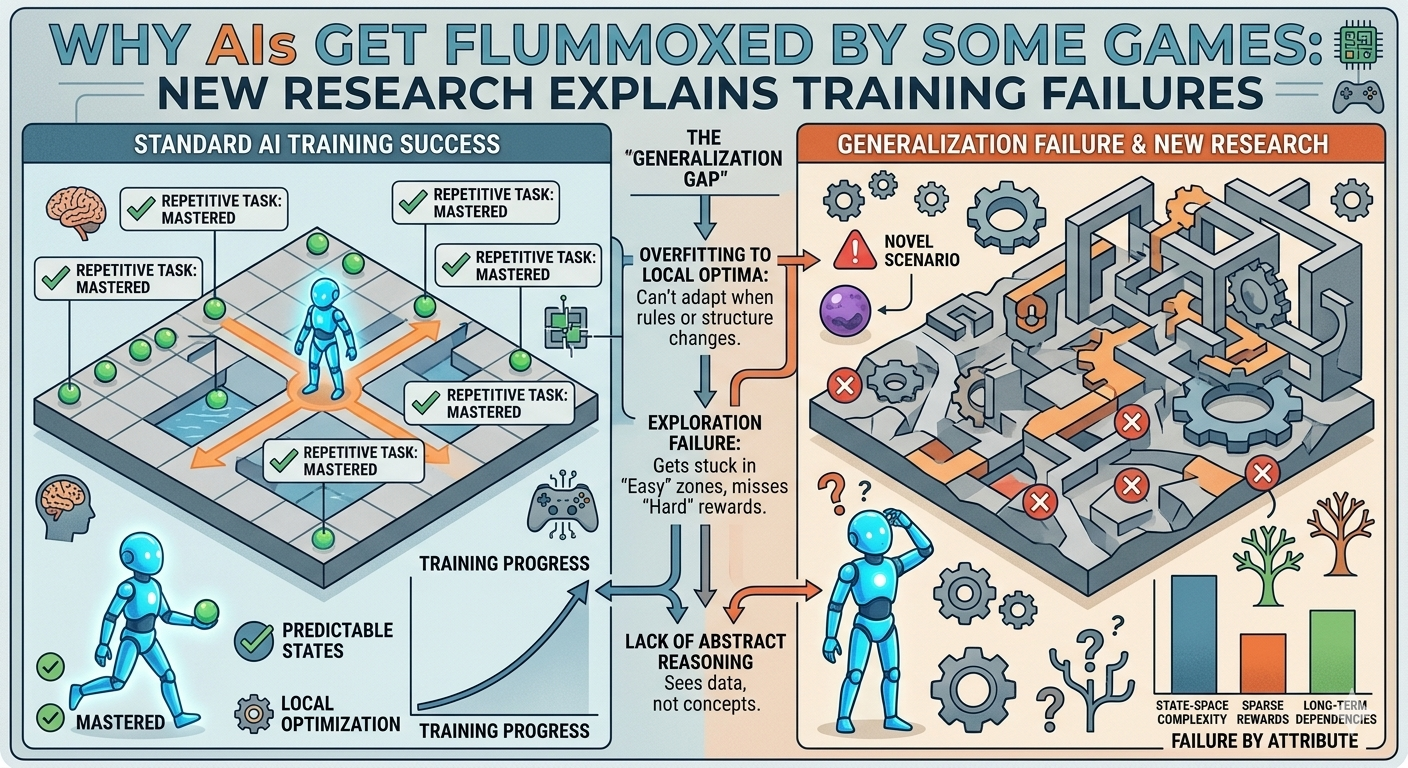
When winning depends on intuiting a mathematical function, AIs come up short. A new paper published in Machine Learning reveals that the training methods powering world-champion game-playing AIs like AlphaGo and AlphaChess fail entirely on an entire category of games—including remarkably simple ones like Nim .
| Detail | Information |
|---|---|
| Research Topic | AI failure modes in impartial games |
| Study Authors | Bei Zhou and Soren Riis |
| Published In | Machine Learning |
| Key Game Studied | Nim (simple matchstick game) |
| Game Category | Impartial games (players share same pieces/rules) |
| Critical Function | Parity function (determines winning positions) |
| Finding | Alpha-style training cannot learn parity functions |
| Implication | Symbolic reasoning remains beyond current methods |
Impartial games differ from something like chess, where each player has their own set of pieces. In impartial games, the two players share the same pieces and are bound by the same set of rules . Nim, the game studied, is a critical example:
Nim’s importance stems from a theorem showing that any position in an impartial game can be represented by a configuration of a Nim pyramid . If something applies to Nim, it applies to all impartial games.
One distinctive feature of impartial games is that at any point, you can evaluate the board and determine which player has the potential to win by feeding the configuration into a parity function —simple math that tells you whether you’re winning .
The researchers asked a simple question: What happens if you take the AlphaGo approach—training an AI purely by playing itself from only the rules—and try to develop a Nim-playing AI? Could it develop a representation of the parity function through self-play ?
| Board Size | Result |
|---|---|
| 5 rows | AI improved quickly, still learning after 500 iterations |
| 6 rows | Rate of improvement slowed dramatically |
| 7 rows | Gains stopped entirely by 500 iterations |
For a seven-row Nim board, the trained AI was indistinguishable from a random move generator . When asked to evaluate all potential moves, it rated every one as roughly equivalent—even though three optimal winning moves existed .
The researchers concluded that Nim requires learning the parity function to play effectively, and Alpha-style training is incapable of doing so .
The researchers found signs that similar problems can crop up in chess-playing AIs:
In Nim, optimal winning branches must be played out to the end to demonstrate their value, making this sort of avoidance much harder .
“AlphaZero excels at learning through association but fails when a problem requires a form of symbolic reasoning that cannot be implicitly learned from the correlation between game states and outcomes.”
— Zhou and Riis
Even when rules enable simple mathematical formulas for deciding what to do, Alpha-style training cannot identify them. The result is a “tangible, catastrophic failure mode” .
| Application | Concern |
|---|---|
| Math Problems | Often require symbolic reasoning, not just association |
| Scientific Discovery | May need extrapolation from data to general rules |
| AI Safety | Failure modes could exist in critical systems |
| Training Design | Need new approaches beyond self-play |
Lots of people are exploring AI for math problems, which often require the sort of symbolic reasoning involved in extrapolating from examples to general rules like the parity function. While it may not be obvious how to train an AI to do that, it’s useful to know which approaches will clearly not work .
| Takeaway | Details |
|---|---|
| Impartial games | Category including Nim where players share pieces/rules |
| Parity function | Simple math determines winning positions—but AIs can’t learn it |
| Training failure | Alpha-style self-play fails entirely on 7-row Nim |
| Broader relevance | Similar blind spots exist in chess/Go AI |
| Symbolic reasoning | Current methods cannot learn what they can’t associate |