Table of Contents
Click any section below to jump directly to that part of the article.
- The Anatomy of a Transformer
- Tokenization: How AI Reads Your Words
- Attention: The Most Important Mechanism
- Positional Encoding: Keeping Track of Order
- How a Language Model Predicts the Next Word
- Temperature, Top‑K, and Top‑P: Controlling Creativity
- Why Larger Models Perform Better
- The Hidden Layer Problem: Interpretability
- Alignment: Making Models Behave
- The Future of Language Model Architecture
The Anatomy of a Transformer
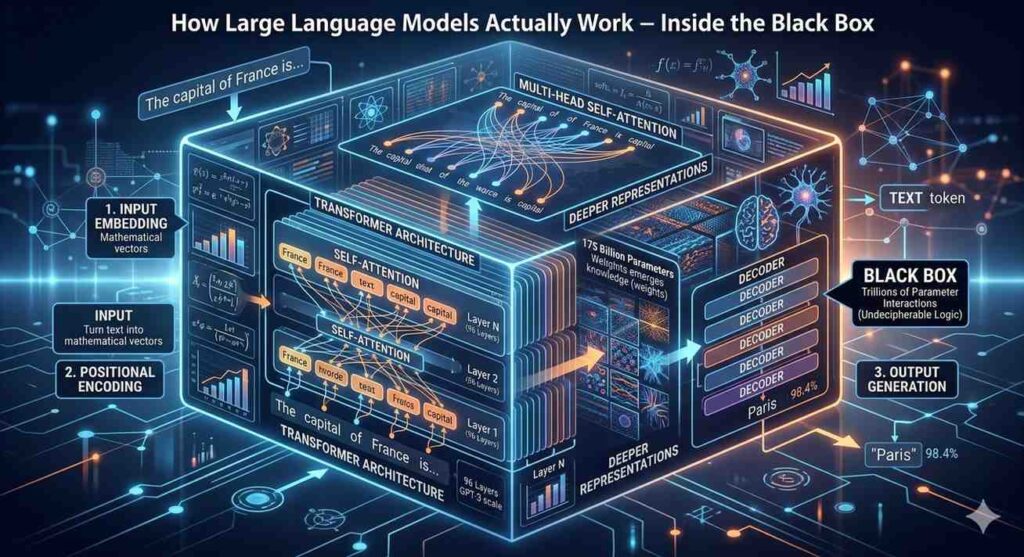
Every modern language model (from GPT‑4 to Gemini to Llama) is built on a single architecture: the transformer. Introduced in 2017, the transformer replaced older recurrent neural networks because it can process words in parallel rather than one after another. This parallelization is what enables models to train on trillions of words.
The transformer has two main parts:
- Encoder – reads and understands the input (used in Google’s BERT).
- Decoder – generates output word by word (used in GPT models).
Most chatbots today are decoder‑only transformers. They take a prompt and produce a continuation. The decoder consists of dozens of stacked layers, each containing two sub‑layers: a self‑attention mechanism and a feed‑forward neural network.
For a broader view of AI models, see our types of artificial intelligence post.
Tokenization: How AI Reads Your Words
Language models do not see characters or words. They see numbers called tokens. Tokenization is the process of breaking text into these atomic units.
A token is typically a sub‑word. For example, the sentence “I love AI” might become:
I→ token 32love→ token 1278AI→ token 502
Space and punctuation have their own tokens.
Why sub‑words? If the model only used words, it could not handle unknown words like “ChatGPT‑4.5” or typos. Sub‑word tokenization (e.g., Byte‑Pair Encoding) splits rare words into common pieces. “Tokenization” might become “token” + “ization”.
Most models have a vocabulary of 50,000 to 100,000 tokens. Every token has a corresponding embedding – a long list of numbers (often 768 to 4,096 numbers) that represent its meaning in vector space.
Real example: In many models, the tokens for “king” and “queen” have a similar mathematical relationship as “man” and “woman.” This is learned during training.
For a practical understanding of how models represent meaning, see our machine learning basics post.
Attention: The Most Important Mechanism
Attention is the reason transformers work so well. It answers the question: Which previous words matter most when predicting the next word?
In the sentence “The cat sat on the ___,” the model should pay attention to “cat” and “sat” to predict “mat.” The attention mechanism computes a weight for every previous word – some high, some near zero.
How it works mathematically:
- Each token has three vectors: Query (what am I looking for?), Key (what do I offer?), and Value (what information do I carry?).
- The model computes the dot product between every token’s Query and every previous token’s Key. This produces an attention score.
- Scores are normalized using a softmax function, so they sum to 1.
- The model multiplies each Value by its attention score and sums them all.
This is called self‑attention because the sequence attends to itself. In practice, models use multi‑head attention – eight to 128 separate attention mechanisms running in parallel, each learning different relationships (e.g., one head learns grammar, another learns coreference resolution, another learns sentiment).
For a deeper dive into attention variants, see our deep learning explained post.
Positional Encoding: Keeping Track of Order
Attention does not inherently know the order of words. It treats a sequence as a bag of tokens. “Cat bit dog” and “Dog bit cat” would have the same attention pattern without position information.
Positional encoding solves this. Before the input enters the first layer, the model adds a unique vector to each token’s embedding – a vector that depends on the token’s position in the sequence (first, second, third …).
There are two types of positional encoding:
| Type | How It Works | Used In |
|---|---|---|
| Absolute | Each position gets a fixed, predefined vector (using sine/cosine functions). | Original transformer |
| Relative | The model learns relationships between positions (e.g., five tokens apart) rather than absolute numbers. | GPT‑4, Llama 2+ |
Relative encoding has proven more effective for long sequences because it generalizes to text lengths not seen during training. Some newer models use rotary positional embeddings (RoPE) which rotate vectors as if on a circle, preserving relative distance naturally.
How a Language Model Predicts the Next Word
When you send a prompt to a model, here is what happens under the hood:
- Tokenization – Your prompt (e.g., “Explain quantum computing”) is split into tokens.
- Embedding – Each token is replaced with its embedding vector (a long list of numbers).
- Positional encoding – Position vectors are added to the embeddings.
- Stacked transformer layers – The tokens pass through 12 to 120 layers of self‑attention and feed‑forward networks. Each layer refines the representation.
- Output logits – The final layer produces a logit (raw score) for every token in the vocabulary.
- Softmax – Logits are converted to probabilities (all tokens sum to 100%).
- Sampling – The model randomly picks the next token based on those probabilities (not always the highest).
That token becomes the first token of the response. The model then appends it to the input and repeats steps 4–7 until it meets a stop condition (e.g., maximum length or a special <end> token).
Important: The model does not read its output as a human would. It only sees previous tokens one at a time. This is called autoregressive generation. It is why models cannot revise a sentence after writing it – they only move forward.
For a high‑level overview of inference, see our AI inference explained post.
Temperature, Top‑K, and Top‑P: Controlling Creativity
The model’s probability distribution often has one token with very high probability. If the model always picks that token, responses become deterministic and boring. To add variety, developers use three parameters:
Temperature – Scales the logits before softmax. Higher temperature (e.g., 1.2) flattens the distribution, making low‑probability tokens more likely. Lower temperature (e.g., 0.2) makes the model nearly deterministic. Temperature 0 is deterministic (always picks the highest probability token).
Top‑K sampling – Only consider the K most likely tokens (e.g., top 50). The rest are ignored. Prevents picking extremely unlikely nonsense.
Top‑P (nucleus) sampling – Choose the smallest set of tokens whose cumulative probability exceeds P (e.g., 0.9). This adaptively includes more tokens when the distribution is flat, and fewer when it is peaky.
Most models use a combination: top‑P = 0.9, temperature = 0.7. For creative writing, developers set temperature higher; for factual Q&A, they set it very low.
Why this matters: The creativity parameter is why the same prompt can give different answers each time – and why the model can hallucinate. For more on hallucinations, see our AI overreliance consequences case studies post.
Why Larger Models Perform Better
In 2020, OpenAI discovered a power law: as you increase model size, dataset size, and compute, performance improves predictably. This led to the “bigger is better” era.
| Model | Parameter Count | Training Tokens | Performance (relative) |
|---|---|---|---|
| GPT‑2 | 1.5 billion | 40 billion | 1× |
| GPT‑3 | 175 billion | 500 billion | 3× |
| GPT‑4 | ~1.8 trillion | ~13 trillion | 5× |
Why does size help? More parameters allow the model to store more patterns and relationships. A small model might learn that “Paris is the capital of France.” A large model learns thousands of supporting facts: population, geography, history, culture – and how they relate. This allows it to reason, analogize, and answer questions never seen during training.
The trade‑offs: Larger models are slower, more expensive, and require more memory. A 175‑billion parameter model needs 350GB of GPU memory just to load its weights. That is why companies use quantization (reducing precision from 32‑bit to 8‑bit) to run them on consumer hardware.
For the impact of AI on hardware pricing, see our AI chip demand and console price trends 2026.
The Hidden Layer Problem: Interpretability
We do not know exactly what happens inside a large language model. The activations (numbers flowing through layers) are not human‑readable. This is called the black box problem.
Researchers try to interpret models using:
- Probes – Train a small classifier to predict a property (e.g., “is the current word plural?”) from the internal activations. If the classifier works, the model must be encoding that property.
- Attention visualization – Show attention weights as heat maps. You can see which words the model focuses on.
- Mechanistic interpretability – Reverse‑engineer circuits within the model. For example, some GPT‑2 layers implement a “copy” circuit that moves information from earlier tokens to later ones.
- Steering vectors – Find a direction in activation space that corresponds to a concept (e.g., “formal language”), then push activations in that direction to change the output without retraining.
Despite these tools, even the researchers who built the models cannot fully explain their decisions. This is a major challenge for safety and regulation.
For ongoing AI safety discussions, see our AI ethics and bias post.
Alignment: Making Models Behave
After training on internet text, models learn patterns – including toxic, biased, or harmful ones. Alignment is the process of steering models toward helpful, harmless, and honest behavior.
The dominant alignment method is Reinforcement Learning from Human Feedback (RLHF) :
- Collect human preferences – Humans rank two model responses to the same prompt (e.g., which is more helpful?).
- Train a reward model – A separate AI learns to predict the human preference score.
- Fine‑tune the language model – Through reinforcement learning, the model learns to maximize the reward model’s score.
RLHF is why ChatGPT answers politely, refuses harmful requests, and generally stays on topic. However, RLHF also causes sycophancy – the model will agree with your incorrect opinion just to be agreeable. For examples, see our sycophantic AI examples post.
Newer alignment techniques include:
- Constitutional AI – The model follows a set of written principles (e.g., “do not be racist”) without human preferences.
- Direct Preference Optimization (DPO) – Simpler and more stable than RLHF.
Even with alignment, no model is perfectly safe. Prompt injection, jailbreaks, and systematic biases remain unsolved.
The Future of Language Model Architecture
The transformer is not the end. Researchers are actively developing new architectures:
State space models (e.g., Mamba) – Replace attention with a compressed state that grows slowly with context length. They can handle millions of tokens at a fraction of the compute cost. However, they underperform transformers on complex reasoning – for now.
Mixture of Experts (MoE) – Already used in GPT‑4. Only a fraction of parameters are activated per token. This reduces inference cost while maintaining large total parameter counts.
Hybrid architectures – Combine attention for some layers and state space for others. This balances quality and efficiency.
Test‑time compute – Instead of scaling the model, run it multiple times and let it reflect, correct, and verify its own output. This improves quality without retraining. o1 and R1 models use this approach.
On‑device models – Small, optimized models that run entirely on phones, laptops, or cars. They protect privacy and work offline. Apple’s neural engine and Qualcomm’s NPU are enabling this shift.
For predictions on where AI is heading, see our emerging tech trends 2026 guide post.
Frequently Asked Questions
Q: Does a language model truly understand language?
No. It predicts patterns. Some argue that statistical approximation of meaning is a form of understanding; others disagree. There is no consensus.
Q: How long does it take to train a large model?
On a cluster of 25,000 GPUs, GPT‑4 took roughly three months. Smaller models take days.
Q: Why do models sometimes repeat themselves?
Repeat loops happen when attention focuses too much on recent tokens and loses the context. This is called “degeneration.” Lowering temperature or using repetition penalties helps.
Q: What is the largest model in terms of parameters?
Google’s Gemini Ultra (2025) reportedly has over 2 trillion parameters. Sparse mixture‑of‑expert models claim far more, but only a fraction are active per token.
Q: Can I see the internal activations of my own GPT query?
Not easily. OpenAI and others do not provide access to internal representations. Some open models (Llama, Mistral) allow full inspection if you run them locally.
Q: Will larger models eventually solve reasoning?
Not automatically. Scaling has diminishing returns. Researchers believe new architectures or inference techniques are also necessary.
